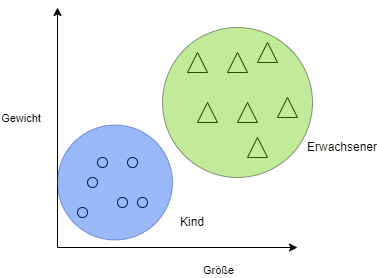
Definition
Das Clustering ist ein bedeutendes Verfahren im Bereich des maschinellen Lernens und der Datenanalyse. Es handelt sich dabei um eine Technik des unüberwachten Lernens, bei der ähnliche Datenpunkte in Gruppen zusammengefasst werden. Das Hauptziel besteht darin, ähnliche Muster und Strukturen in den Daten zu entdecken und diese zu identifizieren, ohne dass die genauen Klassen oder Labels der Datenpunkte im Voraus bekannt sind.
Einsatzgebiete des Clusterings
Clustering findet in verschiedenen Bereichen Anwendung, darunter:
-
Datenanalyse
Clustering hilft, große Datenmengen zu segmentieren und Gruppen von ähnlichen Datenpunkten zu identifizieren. Es wird oft zur explorativen Datenanalyse eingesetzt, um Muster und Zusammenhänge in den Daten zu erkennen.
-
Mustererkennung
In der Bildverarbeitung und der Mustererkennung kann es verwendet werden, um ähnliche Merkmale in Bildern oder Mustern zu gruppieren.
-
Kundensegmentierung
Unternehmen nutzen Clustering, um ihre Kunden in Gruppen mit ähnlichen Eigenschaften zu unterteilen. Dadurch können gezielte Marketingstrategien entwickelt und personalisierte Angebote bereitgestellt werden.
-
Anomalieerkennung
Durch die Identifizierung von Clustern können auch Anomalien erkannt werden, da Datenpunkte, die nicht zu den gefundenen Gruppen passen, als Ausreißer betrachtet werden.
-
Medizinische Diagnose
In der Medizin kann es dazu verwendet werden, Patientengruppen mit ähnlichen Symptomen oder Krankheitsbildern zu identifizieren.
Methoden des Clusterings
Es gibt verschiedene Clustering-Methoden, die je nach Art der Daten und den Anforderungen der Analyse eingesetzt werden. Die bekanntesten Methoden sind:
-
K-Means
Dies ist eine der häufigsten Methoden. Der Algorithmus versucht, die Datenpunkte in K Gruppen zu unterteilen, wobei K eine vorgegebene Anzahl von Clustern ist. Der Algorithmus iteriert immer wieder durch die Daten, um die Clusterzentren so zu optimieren, dass die Datenpunkte innerhalb jedes Clusters möglichst ähnlich sind.
-
Hierarchisches Clustering
Diese Methode erstellt eine Hierarchie von Clustern, die in Form eines Baums (Dendrogramm) dargestellt werden kann. Es gibt zwei Ansätze: Agglomeratives Clustering, bei dem jeder Datenpunkt als eigenes Cluster beginnt und dann schrittweise zu größeren Clustern verschmolzen wird, und Divisives Clustering, bei dem alle Datenpunkte zunächst zu einem Cluster gehören und dann schrittweise in kleinere Cluster aufgeteilt werden.
-
Dichtebasiertes Clustering
Hier werden Cluster anhand der Dichte der Datenpunkte definiert. Datenpunkte, die in dichten Regionen liegen, werden zu Clustern zusammengefasst, während Bereiche mit geringer Dichte als Trennung zwischen den Clustern dienen.
Fazit
Clustering ist eine leistungsfähige Methode, um Strukturen und Muster in großen Datensätzen zu entdecken und zu verstehen. Es findet in verschiedenen Bereichen Anwendung und ist ein wichtiger Bestandteil vieler Datenanalyse- und maschineller Lernverfahren. Durch das Erkennen von Ähnlichkeiten und Gruppen in den Daten ermöglicht Clustering eine bessere Informationsgewinnung, Entscheidungsfindung und die Entwicklung effektiverer Strategien in verschiedenen wissenschaftlichen, geschäftlichen und technischen Bereichen.