Qualitätsstandards bei KI-Lösungen
Qualitätsstandards bei KI-Lösungen beziehen sich auf die Maßnahmen und Praktiken, die bei der Entwicklung, Implementierung und dem Einsatz von Künstlicher Intelligenz (KI) angewendet werden, um sicherzustellen, dass die Ergebnisse und Funktionalitäten der KI-Lösungen den Anforderungen und E...
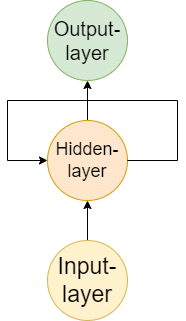
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) sind eine spezielle Klasse von künstlichen neuronalen Netzwerken, die entwickelt wurden, um sequenzielle Daten effektiv zu verarbeiten. Im Gegensatz zu herkömmlichen Feedforward-Netzwerken können RNNs Informationen über vorherige Zustände speichern, was sie be...
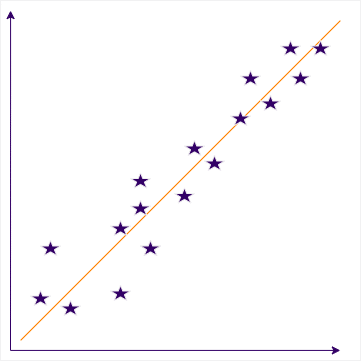
Regression bei künstlicher Intelligenz
Regression ist ein grundlegender Begriff im Bereich Künstlicher Intelligenz (KI) und bezieht sich auf eine spezielle Art des maschinellen Lernens. Es ist ein statistisches Verfahren, das es KI-Modellen ermöglicht, Zusammenhänge zwischen verschiedenen Variablen zu analysieren und Vorhersagen...
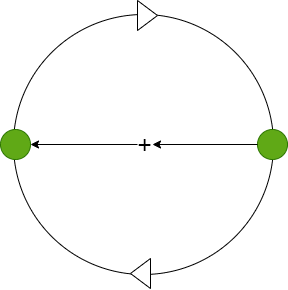
Reinforcement Learning
Das Reinforcement Learning basiert auf dem Konzept des Lernens durch Belohnung und Bestrafung. Dabei verfolgt diese Art von Lernen ein komplett anderes Konzept aus Supervised oder Unsupervised Learning. Der Agent interagiert mit einer bestimmten Umgebung und erhält Feedback in Form von Belohnu...
Risiko in der künstlichen Intelligenz
Die Entwicklung und Anwendung von Künstlicher Intelligenz birgt Chancen und Risiken. Die genannten Risiken, wie fehlende Transparenz, Vorurteile und Diskriminierung, Datenschutz- und Sicherheitsbedenken, Arbeitsplatzverluste und der Verlust menschlicher Kontrolle, erfordern eine umsichtige Hera...
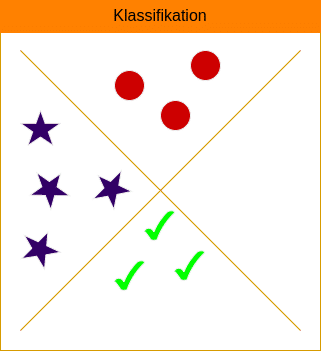
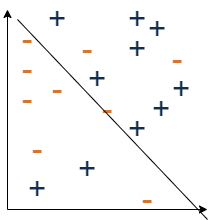
Supervised Learning - Der Lernprozess
Im Supervised Learning wird ein KI-Modell auf Grundlage von gelabelten Trainingsdaten trainiert, um eine Funktion zu erlernen, die die Eingabedaten auf die entsprechenden Ausgabewerte abbildet. Die gelabelten Daten bestehen aus Eingabe-Ausgabe-Paaren, bei denen jede Eingabe mit einem entspreche...
Synthetische Daten - Methoden und Verwendung
Synthetische Daten sind künstlich generierte Daten, die entweder auf Basis statistischer Modelle oder algorithmischer Verfahren erstellt werden. Im Gegensatz zu echten Daten werden diese Daten nicht aus tatsächlichen Beobachtungen oder Messungen gewonnen, sondern werden gezielt generiert, um b...
Testdaten - Wichtigkeit und Optimierung
Testdaten sind eine Sammlung von Beispielen, die verwendet werden, um die Leistung eines KI-Modells zu bewerten. Sie bestehen aus Eingabedaten und den erwarteten Ausgabewerten, die das Modell liefern sollte. Diese Daten werden typischerweise von Experten oder menschlichen Beobachtern erstellt, um r...
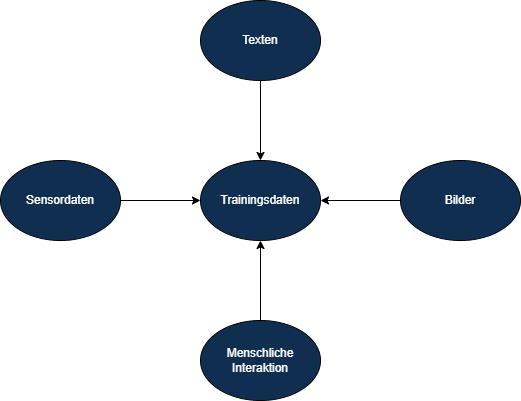
Trainingsdaten bei KI-Projekten
Trainingsdaten sind eine Sammlung von Beispieldaten, die verwendet werden, um KI-Algorithmen zu trainieren. Diese Daten können aus verschiedenen Quellen stammen, wie zum Beispiel aus menschlichen Interaktionen, Sensordaten, Texten oder Bildern. Sie repräsentieren die realen oder simulierten Eing...
Transferlernen in der künstlichen Intelligenz
Das Transferlernen ist ein bedeutendes Konzept in der künstlichen Intelligenz und maschinellen Lernens, das es ermöglicht, Wissen, das in einer bestimmten Aufgabe gelernt wurde, auf andere, verwandte Aufgaben anzuwenden. Dabei geht es darum, Erfahrungen und Kenntnisse, die in einem bestimmten Ko...
Transparenz in der künstlichen Intelligenz
Transparenz bezieht sich auf die Offenlegung von Informationen und Prozessen, die es ermöglicht, die Entscheidungsfindung und Funktionsweise von KI-Systemen nachzuvollziehen.
Bedeutung in der KI
Transparenz spielt eine entscheidende Rolle bei der Gewährleistung einer verantwortungsvollen Nutzung ...
Turing Test in der künstlichen Intelligenz
Der Turing-Test ist ein Begriff aus der Informatik und der künstlichen Intelligenz (KI), benannt nach dem britischen Mathematiker und Informatiker Alan Turing (1912-1954). Der Test wurde erstmals 1950 in Turings Artikel "Computing Machinery and Intelligence" vorgestellt. Das Hauptziel besteht dar...
Unsupervised Learning in der Künstlichen Intelligenz
Unsupervised Learning, auch als unüberwachtes Lernen bezeichnet, ist eine Methode des maschinellen Lernens in der Künstlichen Intelligenz (KI). Im Gegensatz zum überwachten Lernen, bei dem ein Modell mit gelabelten Daten trainiert wird, zielt das unüberwachte Lernen darauf ab, Strukturen und...
Unteranpassung bei künstlicher Intelligenz
Unteranpassung, auch Underfitting genannt, ist ein Begriff, der im Kontext von Künstlicher Intelligenz (KI) und maschinellem Lernen verwendet wird. Es beschreibt eine Situation, in der ein KI-Modell nicht in der Lage ist, ausreichend komplexe Muster in den Trainingsdaten zu erfassen und daher sch...
Validierung (im Kontext von ML)
Die Validierung im Kontext des maschinellen Lernens (ML) bezieht sich auf den Prozess der Bewertung und Überprüfung der Leistung eines Modells anhand von Daten. Es ist ein entscheidender Schritt, um sicherzustellen, dass das Modell korrekte und zuverlässige Ergebnisse liefert.
Vorg...
Verfügbarkeit von KI-Algorithmen
Die Verfügbarkeit von KI bezieht sich auf den Grad, in dem KI-Technologien und -Anwendungen für Unternehmen, Organisationen und Einzelpersonen zugänglich und einsatzbereit sind. Eine hohe Bereitstellung bedeutet, dass KI-Tools und -Lösungen leicht verfügbar, erschwinglich und benutzerfreundli...
Vertrauen bei KI-Systemen
Vertrauen spielt eine entscheidende Rolle in der Beziehung zwischen Menschen und künstlicher Intelligenz (KI). KI-Algorithmen und -Systeme werden zunehmend in verschiedenen Bereichen eingesetzt, von der Medizin über die Finanzbranche bis hin zur Automatisierung von Aufgaben des täglichen Leb...
Vertrauenswürdige Künstliche Intelligenz
Vertrauenswürdige Künstliche Intelligenz (KI) bezieht sich auf den Einsatz von KI-Systemen, die ethisch und verantwortungsvoll entwickelt, implementiert und genutzt werden, um das Vertrauen der Benutzer und der Gesellschaft insgesamt zu gewinnen. Die Schaffung von vertrauenswürdiger KI zielt da...
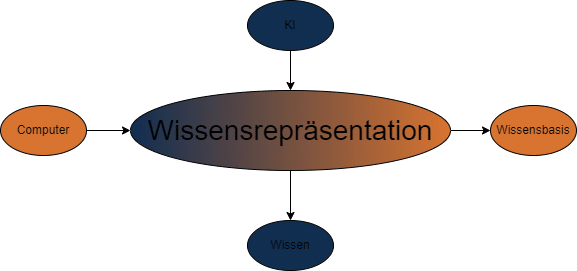
Wissensrepräsentation in der künstlichen Intelligenz
Die Wissensrepräsentation ist ein zentrales Konzept in der künstlichen Intelligenz (KI) und bezieht sich auf die Art und Weise, wie Informationen und Wissen in einem Computersystem dargestellt und verarbeitet werden. Ziel der Wissensrepräsentation ist es, die Welt auf eine für den Computer v...
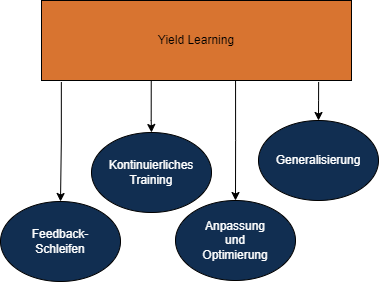
Yield Learning eines KI-Modells
Yield Learning ist ein Konzept im Bereich der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML), das sich auf die Fähigkeit eines KI-Modells bezieht, aus seinen eigenen Fehlern und Erfahrungen zu lernen, um seine Leistung im Laufe der Zeit zu verbessern. Es handelt sich um einen wes...