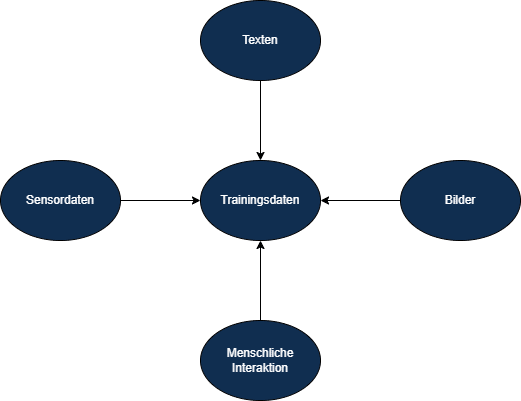
Was sind Trainingsdaten?
Trainingsdaten sind eine Sammlung von Beispieldaten, die verwendet werden, um KI-Algorithmen zu trainieren. Diese Daten können aus verschiedenen Quellen stammen, wie zum Beispiel aus menschlichen Interaktionen, Sensordaten, Texten oder Bildern. Sie repräsentieren die realen oder simulierten Eingaben, auf die die KI später angewendet wird.
Die Bedeutung von qualitativ hochwertigen Daten
Die Qualität der Trainingsdaten hat einen direkten Einfluss auf die Leistungsfähigkeit und Genauigkeit der KI. Hochwertige Daten sollten repräsentativ für das Problem oder die Aufgabe sein, die die KI lösen soll. Sie sollten ausreichend vielfältig sein, um verschiedene Szenarien und Randfälle abzudecken, damit die KI robust und zuverlässig arbeiten kann. Zudem ist es wichtig, dass die Trainingsdaten sorgfältig gelabelt und annotiert werden, um den KI-Algorithmen das Lernen zu ermöglichen.
Datensammlung und -bereinigung
Die Datensammlung und -bereinigung ist ein entscheidender Schritt bei der Vorbereitung der Trainingsdaten. Oftmals werden große Datenmengen aus verschiedenen Quellen gesammelt und dann aufbereitet, um Rauschen, Ausreißer und fehlerhafte Daten zu entfernen. Dieser Prozess erfordert oft manuelle Überprüfungen und Korrekturen, um sicherzustellen, dass sie eine hohe Qualität aufweißt.
Datenvielfalt und -repräsentativität
Um eine gute Leistung der KI zu erzielen, ist es wichtig, dass die Trainingsdaten eine ausreichende Vielfalt und Repräsentativität aufweisen. Dies bedeutet, dass die Daten verschiedene Variationen, Randfälle und Szenarien abdecken sollten, um die KI auf eine breite Palette von Eingaben vorzubereiten. Eine unzureichende Vielfalt kann zu einer eingeschränkten Fähigkeit der KI führen, in realen Anwendungen zu generalisieren.
Ethik und Datenschutz
Bei der Verwendung von Trainingsdaten in KI-Projekten ist es wichtig, ethische Grundsätze und Datenschutzbestimmungen zu beachten. Die Datensammlung sollte transparent und mit Zustimmung der betroffenen Personen erfolgen. Zudem sollten sensible oder persönliche Informationen anonymisiert oder verschlüsselt werden, um die Privatsphäre der Benutzer zu schützen.
Zusammenfassung
Trainingsdaten sind eine wesentliche Komponente bei der Entwicklung von Künstlicher Intelligenz. Sie ermöglichen es den KI-Algorithmen, aus Beispielen zu lernen und Muster zu erkennen. Hochwertige Trainingsdaten, die repräsentativ, vielfältig und sorgfältig gelabelt sind, sind entscheidend für die Leistungsfähigkeit und Zuverlässigkeit der KI. Die Datensammlung und -bereinigung erfordert oft manuelle Überprüfungen, und Datenschutz- und Ethikaspekte sollten bei der Verwendung von Trainingsdaten berücksichtigt werden.
Insgesamt stellen sie einen essenziellen Bestandteil der KI-Entwicklung dar und spielen eine entscheidende Rolle bei der Erreichung von Fortschritten in den Bereichen maschinelles Lernen und Künstliche Intelligenz. Durch die kontinuierliche Verbesserung der Qualität und Verfügbarkeit der Daten können wir immer fortschrittlichere und leistungsfähigere KI-Systeme entwickeln, die unsere Welt auf vielfältige Weise positiv beeinflussen können.