Was ist Supervised Learning?
Im Supervised Learning wird ein KI-Modell auf Grundlage von gelabelten Trainingsdaten trainiert, um eine Funktion zu erlernen, die die Eingabedaten auf die entsprechenden Ausgabewerte abbildet. Die gelabelten Daten bestehen aus Eingabe-Ausgabe-Paaren, bei denen jede Eingabe mit einem entsprechenden Ausgabewert verknüpft ist.
Der Lernprozess
Der Trainingsprozess besteht darin, das Modell so anzupassen, dass es die Beziehung zwischen den Eingaben und den Ausgaben erkennt und generalisiert. Das Modell wird mit einer Menge von Trainingsdaten gefüttert, und basierend auf diesen Daten passt es seine internen Parameter an, um die bestmögliche Vorhersage für neue, unbekannte Daten zu machen.
Es gibt verschiedene Arten von Supervised Learning, abhängig von der Art der Ausgabe, die vorhergesagt werden soll:
-
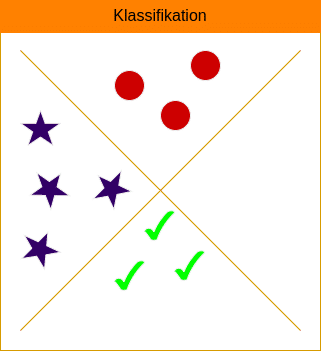
Klassifikation
Bei der Klassifikation werden diskrete Kategorien oder Klassen vorhergesagt. Das Modell wird darauf trainiert, Eingabedaten bestimmten Kategorien zuzuordnen. Zum Beispiel kann ein Modell trainiert werden, um Bilder von Hunden und Katzen zu klassifizieren.
-
Regression
Bei der Regression werden kontinuierliche numerische Werte vorhergesagt. Das Modell lernt eine Funktion, die die Eingabedaten auf einen numerischen Wert abbildet. Ein Beispiel für Regression könnte die Vorhersage des Hauspreises auf Grundlage von Merkmalen wie Größe, Lage und Alter sein.
Der Erfolg des Supervised Learning hängt stark von der Qualität und Repräsentativität der Trainingsdaten ab. Eine ausreichend große und vielfältige Menge an Trainingsdaten ist oft erforderlich, um gute Ergebnisse zu erzielen. Zudem ist die Wahl eines geeigneten Modells und die Feinabstimmung seiner Parameter wichtig, um eine hohe Vorhersagegenauigkeit zu erreichen.
Nachdem das Modell trainiert wurde, kann es auf neue, unbeschriftete Daten angewendet werden, um Vorhersagen zu machen. Die Leistung des Modells kann anhand von Evaluationsmetriken wie Genauigkeit, Präzision, Recall oder Mean Squared Error (MSE) bewertet werden.
Fazit
Supervised Learning ist eine weit verbreitete und nützliche Methode des maschinellen Lernens, die in einer Vielzahl von Anwendungen angewendet wird, um Vorhersagen und Entscheidungen zu treffen.